Gitコマンドを使う際にGitの仕組みを理解しておいた方が覚えやすいようでしたので、この記事ではGitにおけるデータ管理の仕組みをフワッと解説します。
- 変更はファイル単位で変更分のみバージョンとして記録される
- ブランチとは最新バージョンを指している。履歴の流れそのものではない。
- Gitは計4層でバージョン管理されている。CS型かつクライアントの内部3層。
バージョン(リビジョン)管理について
バージョン毎のファイル管理
Gitはバージョン毎に変更があるファイルのスナップショット(ファイルそのもの)を記憶します。
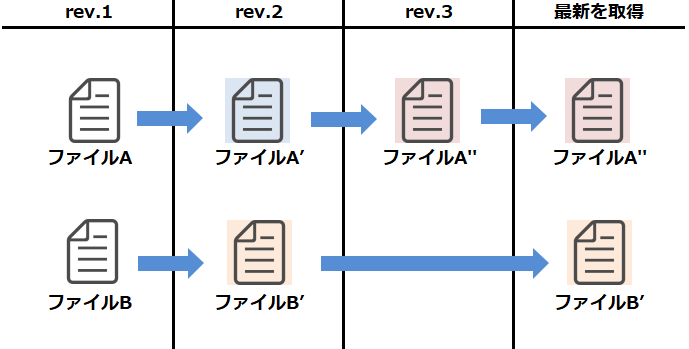 ファイル管理のイメージ。 各バージョン毎にそのバージョンで変更されたファイルそのものを記録しています。(バージョン毎に全ファイルを記憶している、ファイル内の変更部分だけを記憶している とかではない)
ファイル管理のイメージ。 各バージョン毎にそのバージョンで変更されたファイルそのものを記録しています。(バージョン毎に全ファイルを記憶している、ファイル内の変更部分だけを記憶している とかではない)特定のバージョンを取得する際はそのバージョンで最新のファイルを復元します。最新(rev.3)を取得した場合、ファイルA”(rev.3)とファイルB'(rev.2)が展開されますし、rev.2を取得したらファイルA'(rev.2)とファイルB'(rev.2)が展開されます。
ブランチ管理
Gitでは開発リポジトリ内の本流(master)から派生した支流(枝)を作成し、本流に影響がないように開発を行うことができる『ブランチ』という機能を提供しています。
ブランチを作成することで、同じリポジトリ内で異なる改修を相互の影響なく進めることができます。(例えば、masterブランチをリリース版とし、ブランチ①を機能改修、ブランチ②をバグ対応にするなど。)
また、ブランチで変更した内容はmasterに統合することが可能です。これにより並行して開発していた機能を一つのソフトに集約することができます。
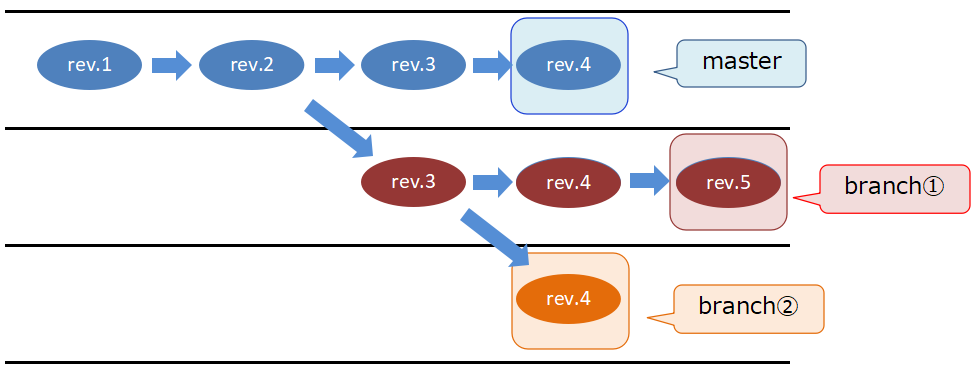 ブランチのイメージ。 作成したブランチ単位で管理できるようになる。
ブランチのイメージ。 作成したブランチ単位で管理できるようになる。
で、ここが重要なんですが
ブランチとは各流れの最新バージョンへのポインタです。流れ自体を指すのではありません。上図では四角で囲ったバージョンだけをそれぞれ指します。つまり、branch①とは赤のrev.5を指します。rev.3からrev.5の一通りの流れではありません。
これはGitコマンドを使用するにあたり重要となるので、しっかり認識してください。
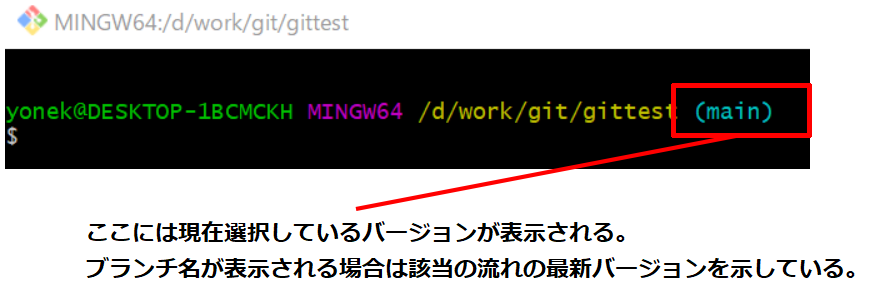
git bash等にブランチ名が表示されますが、これはその流れの最新バージョンをポイントしていることを表しています。
関連用語
HEAD
HEADは複数作成できるブランチと異なり、リポジトリ内にただ一つのみ存在するポインタです。現在操作中のブランチ(=その流れの最新)を指します。
GitではHEADが指し示す先を変更することで操作するブランチを切り替えます。逆に言うと、HEADが現在指しているブランチ以外を操作することはできません。
操作するブランチはcheckoutコマンドで切り替えます。
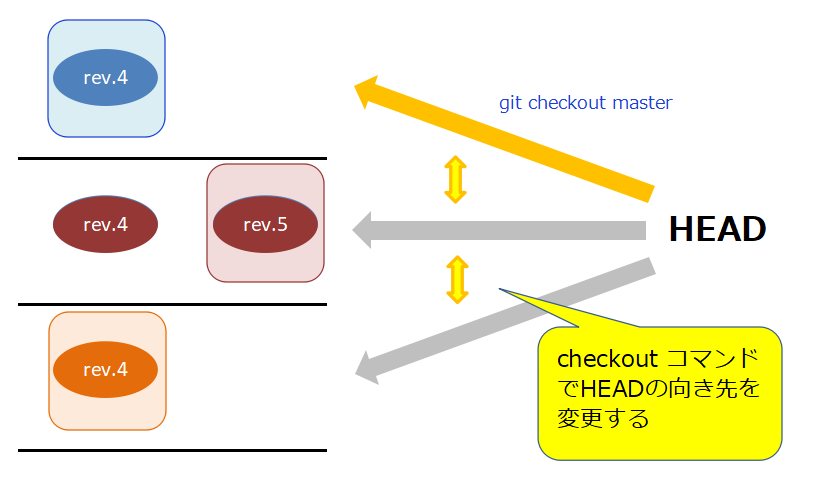 HEADの概念 HEAD⇒master⇒青rev.4という感じでバージョンが特定されるイメージ。
HEADの概念 HEAD⇒master⇒青rev.4という感じでバージョンが特定されるイメージ。
detached HEAD
Gitを操作しているとdetached HEADという状態になることがあります。detached HEADとは、HEADがブランチ(=最新バージョン)でなく、途中のバージョンを指している状態です。
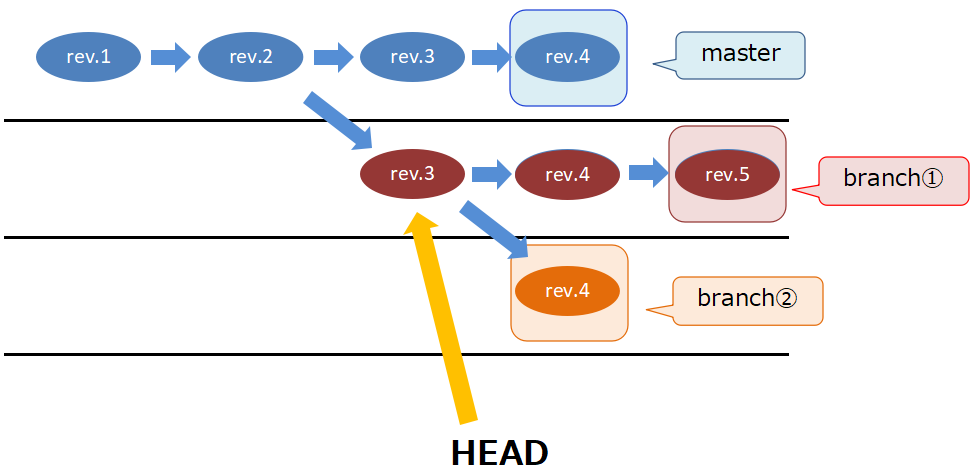 branch①の履歴を指している。この状態がdetached HEAD
branch①の履歴を指している。この状態がdetached HEAD
checkoutコマンドで直接過去バージョンにした場合に発生します。また、rebaseを行った場合等も発生することがあるみたいです。
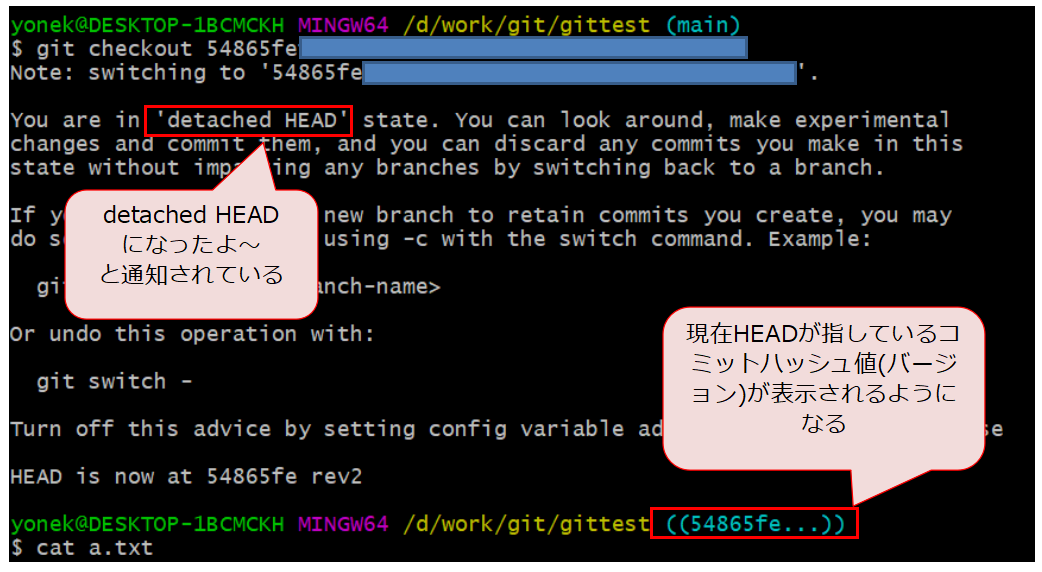 例)checkoutコマンドでローカルを過去の履歴に戻してみた状態
例)checkoutコマンドでローカルを過去の履歴に戻してみた状態上図の例からも分かりますが、git bashのコマンド入力右側に青字で表示されているものはHEADが指しているバージョンです。最新バージョンの時はブランチ名が表示されていることから、やはりブランチ名=最新バージョンを指すと言えます。この辺からも内部の管理の仕組みが分かりますね。
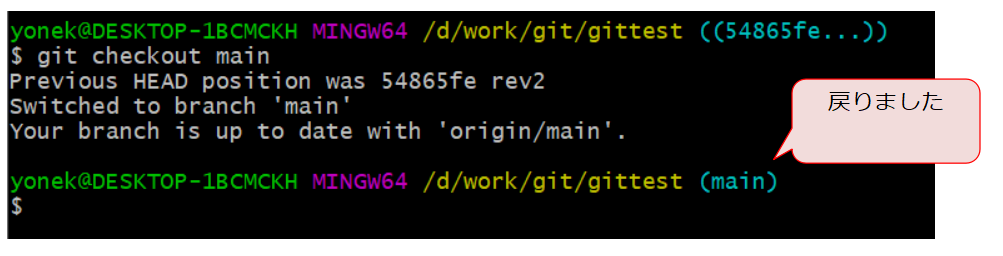
ちなみに過去バージョンから最新に戻したい場合は、ブランチ名を指定してcheckoutすればOKです。ブランチ名=最新バージョンなので。
データ管理の階層
Gitではリモートサーバに変更を登録するまでにaddやcommit、pushなど複数のコマンドを実行する必要があります。これらは複数の階層に分けて変更ファイルを管理しているためです。
ここではこの階層について解説します。
Gitで変更内容をリモートサーバに登録するために必要な操作の例:
- ファイル編集
- ステージング(add/rm/mv)
- ローカルリポジトリへコミット(commit)
- リモートサーバへ登録(push)
クライアントサーバ(CS)構造
Gitはローカル端末上で変更を行いリモートサーバでデータを一元管理します。このため、ローカルで変更した内容をリモートサーバ上のリポジトリ(リモートリポジトリ)に反映する操作が必要となります。この時にpushコマンドを使用します。
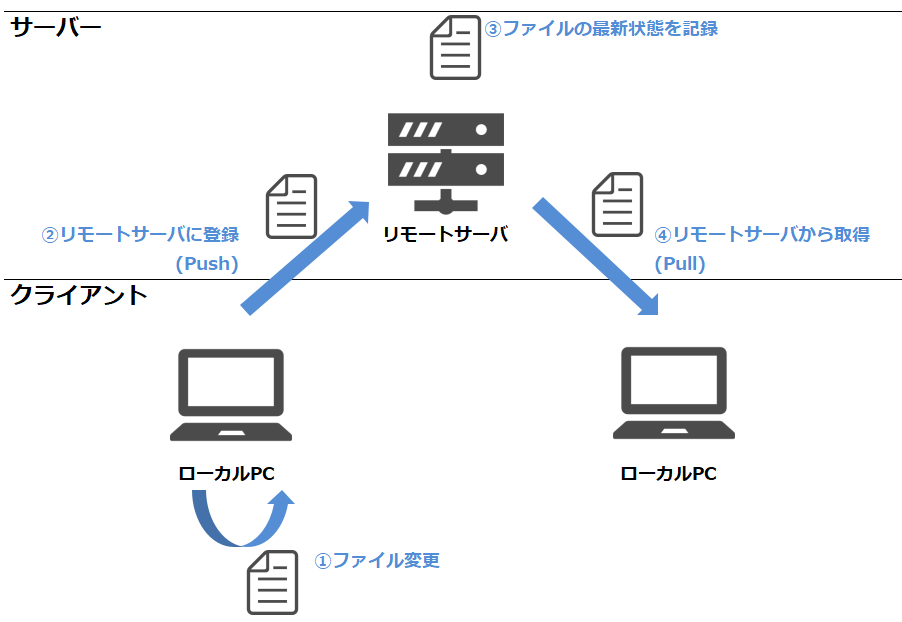 端末の階層構造。 ローカルからサーバに反映する場合はpushコマンド、サーバからローカルに取得する場合はpullを使う。(取得するコマンドはほかにもfetchとかmergeがある)
端末の階層構造。 ローカルからサーバに反映する場合はpushコマンド、サーバからローカルに取得する場合はpullを使う。(取得するコマンドはほかにもfetchとかmergeがある)ローカルPC上の管理構造
GitではローカルPC上でも3層に分けて変更を管理しています。
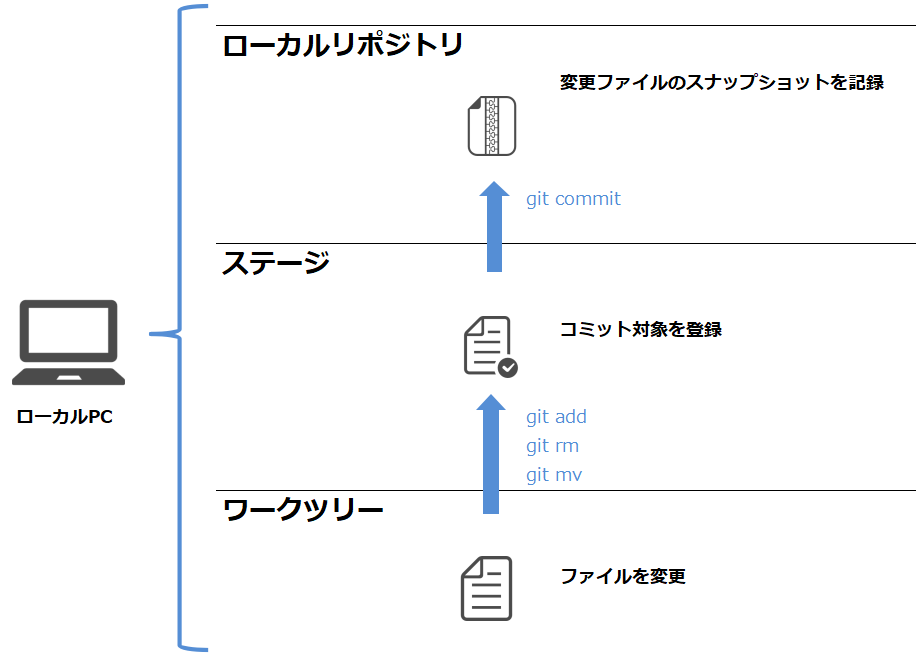 ワークツリー、ステージ、ローカルリポジトリの3層に分かれている。
ワークツリー、ステージ、ローカルリポジトリの3層に分かれている。ワークツリー
ワークツリーとは、Gitの管理下に置かれたフォルダ(ディレクトリ)のことです。皆さんが実際に修正するファイルが配置されています。
ステージ
ステージとは、ローカルリポジトリにコミットする対象となるファイルを登録するための領域です。ワークツリーで変更したファイルをadd/rm/mvコマンドでステージに登録します。(ステージングと呼ばれます)
ステージが存在することにより、現在編集中のファイルの内、必要なファイルだけを選んでコミットすることができるようになります。(例えば、まだ途中のファイルはコミットせず、特定のファイルだけ先行してコミットしたい場合など。)
ステージングしていないファイルは変更があってもコミットされないため、コミット漏れに注意してください。
SVNで言うところの、コミット画面でコミット対象ファイルをチェックボックスで選ぶ操作に相当するイメージです。
ローカルリポジトリ
ローカルPC上に存在するリポジトリです。ステージに登録された変更内容を一つのバージョンとして記録します。commitコマンドでローカルリポジトリにコミットします。
リモートリポジトリとの窓口となっており、ローカルリポジトリの内容がpushコマンドでリモートリポジトリに登録されます。逆はpullコマンド。
まとめ
というわけで、長くなりましたがGitの基本的な仕組みについて簡単に解説してみました。コマンドの理解に必要なところをピックアップしたつもりなので、お役に立てば幸いです。
勉強中の身ですので、誤りや不備等ありましたらご指摘いただけるとありがたいです。







